Memory coalescing in CUDA (2) – Matrix Transpose
cuda basics techTable of Contents
Background
In the VecAdd page, we’ve introduced the memory coalescing in global memory access. This post will follow the topic with another interesting application: Matrix transposing.
The following content will briefly touch on the following topics:
- Tiles in matrix, this is the basis of optimization matrix computation
- A simple trick to avoid bank conflict in shared memory access
Kernels
The code for all the kernels locates in 1-matrix-transpose-coalesce.cu.
Read coalesced
template <typename T>
__global__ void transpose_read_coalesce(
const T* __restrict__ input,
T* __restrict__ output,
int n,
int m) {
int i = blockIdx.x * blockDim.x + threadIdx.x; // the contiguous tid
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < n && j < m) {
output[i * m + j] = input[j * n + i];
}
}
Write coalesced
template <typename T>
__global__ void transpose_write_coalesce(
const T* __restrict__ input,
T* __restrict__ output,
int n,
int m) {
int i = blockIdx.x * blockDim.x + threadIdx.x; // the contiguous tid
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < n && j < m) {
output[j * n + i] = input[i * m + j];
}
}
Both read and write coalesced by tiling with shared memory
The tiling method is a common methodology for optimizing matrix operation. It divides the matrix into smaller, manageable blocks or “tiles” that can fit into shared memory.
Let’s divide the matrix into tiles of size \(TILE \times TILE\), and the overall transpose could be decoupled into two sub-levels:
- the inter-tile transpose, that is move the tile to the target position; and secondly,
- the intra-tile transpose, that is transpose the elements within a single tile
Inter-tile transpose
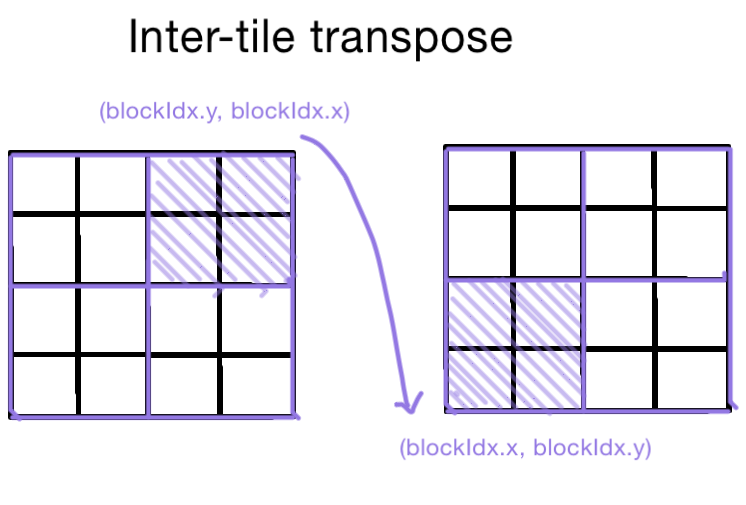
Each tile is processed by a thread block, so the tile coordinate is (blockIdx.y, blockIdx.x), and the target coord is (blockIdx.x, blockIdx.y).
We can continue to process the elements within each tile.
Intra-tile transpose
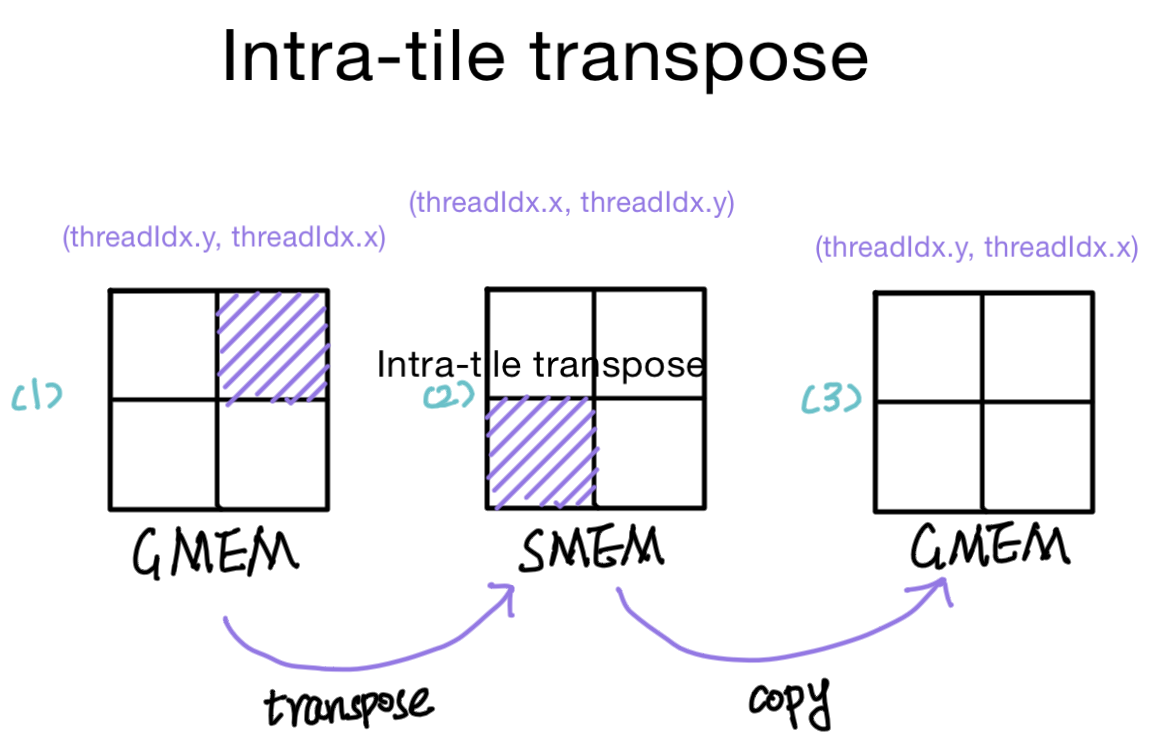
Within a tile, we will read the elements, store the transposed version in the shared memory, and then store the tile in global memory, with the coord determined by the intra-tile transpose phase.
There are two copies:
- Copying the tile from the input matrix and storing a transposed version into shared memory
- Copying the tile from shared memory into the output matrix in global memory
Only one side is in global memory in both copies, so it can perform a memory coalescing access pattern. Both copies are performed by all the threads collectively within a thread block.
To make a coalesced memory access, in the first copy, a thread reads element of coord of (threadIdx.y, threadIdx.x), and the memory offset threadIdx.y * M + threadIdx.x is contignuous for adjacent threads.
In the second copy, the thread block needs to copy a tile to global memory, similarly, a thread should process the element of (threadIdx.y, threadIdx.x) in the output tile.
Kernel with constant tile size
template <typename T, int TILE>
__global__ void transpose_tiled_coalesce0(
const T* __restrict__ input,
T* __restrict__ output,
int n,
int m) {
assert(blockDim.x == blockDim.y && blockDim.x == TILE_DIM);
// TILE + 1 to avoid bank conflict
// By padding the shared memory array with an extra element, the consecutive threads access
// memory locations that fall into different banks to avoid bank conflict
__shared__ T tile[TILE][TILE + 1];
int i = blockIdx.y * blockDim.y + threadIdx.y;
int j = blockIdx.x * blockDim.x + threadIdx.x;
if (i < m && j < n) {
tile[threadIdx.x][threadIdx.y] = input[i * n + j];
}
__syncthreads();
i = blockIdx.x * blockDim.x + threadIdx.y;
j = blockIdx.y * blockDim.y + threadIdx.x;
if (i < n && j < m) {
output[i * m + j] = tile[threadIdx.y][threadIdx.x];
}
}
Note that, since each thread processes only one element, so both blockDim.x and blockDim.y should equal to TILE, and TILE is a constant value.
Kernel with dynamic tile size
It is possible to allocate the shared memory dynamically, making the TILE a variable that could be assigned with blockDim.x or blockDim.y on the fly.
template <typename T>
__global__ void transpose_tiled_coalesce1(
const T* __restrict__ input,
T* __restrict__ output,
int n,
int m) {
const size_t TILE = blockDim.x;
assert(blockDim.x == blockDim.y);
extern __shared__ T tile[];
int i = blockIdx.y * blockDim.y + threadIdx.y;
int j = blockIdx.x * blockDim.x + threadIdx.x;
if (i < m && j < n) {
tile[threadIdx.x * (TILE + 1) + threadIdx.y] = input[i * n + j];
}
__syncthreads();
i = blockIdx.x * blockDim.x + threadIdx.y;
j = blockIdx.y * blockDim.y + threadIdx.x;
if (i < n && j < m) {
output[i * m + j] = tile[threadIdx.y * (TILE + 1) + threadIdx.x];
}
}
Performance
In NVIDIA GTX 3080, these kernels have a pretty close performance:
| Kernel | Latency |
|---|---|
| Read coalesced | 0.0476 |
| Write coalesced | 0.0474 |
| tiled | 0.0478 |